 Поделиться
Поделиться
Российские компании предлагают собственные технологии для работы с большими данными
Сегодня уже невозможно представить себе компанию, которая не использует возможности больших данных для анализа и прогнозирования бизнес-процессов. Появляются все новые инструменты и технологии, которые делают анализ больших данных удобным. Главное — убедить пользователей работать с ними как можно больше, уверены участники организованной CNews Conferences конференции «Большие данные 2024».
Чего ждать от «Экономики данных»
В следующем году главной программой цифровизации в России станет национальный проект «Экономика данных». Глеб Шуклин, руководитель стратегических проектов Ассоциации больших данных, рассказал о том, какие новые возможности принесет он рынку. Его паспорт должен быть утвержден в ближайшее время. Предполагалось, что объем финансирование нацпроекта должен составить около 1,5 млрд руб. Однако в послании Президента Федеральному собрания была озвучена цифра 700 млрд руб.
Планы финансирования нацпроекта «Экономика данных»
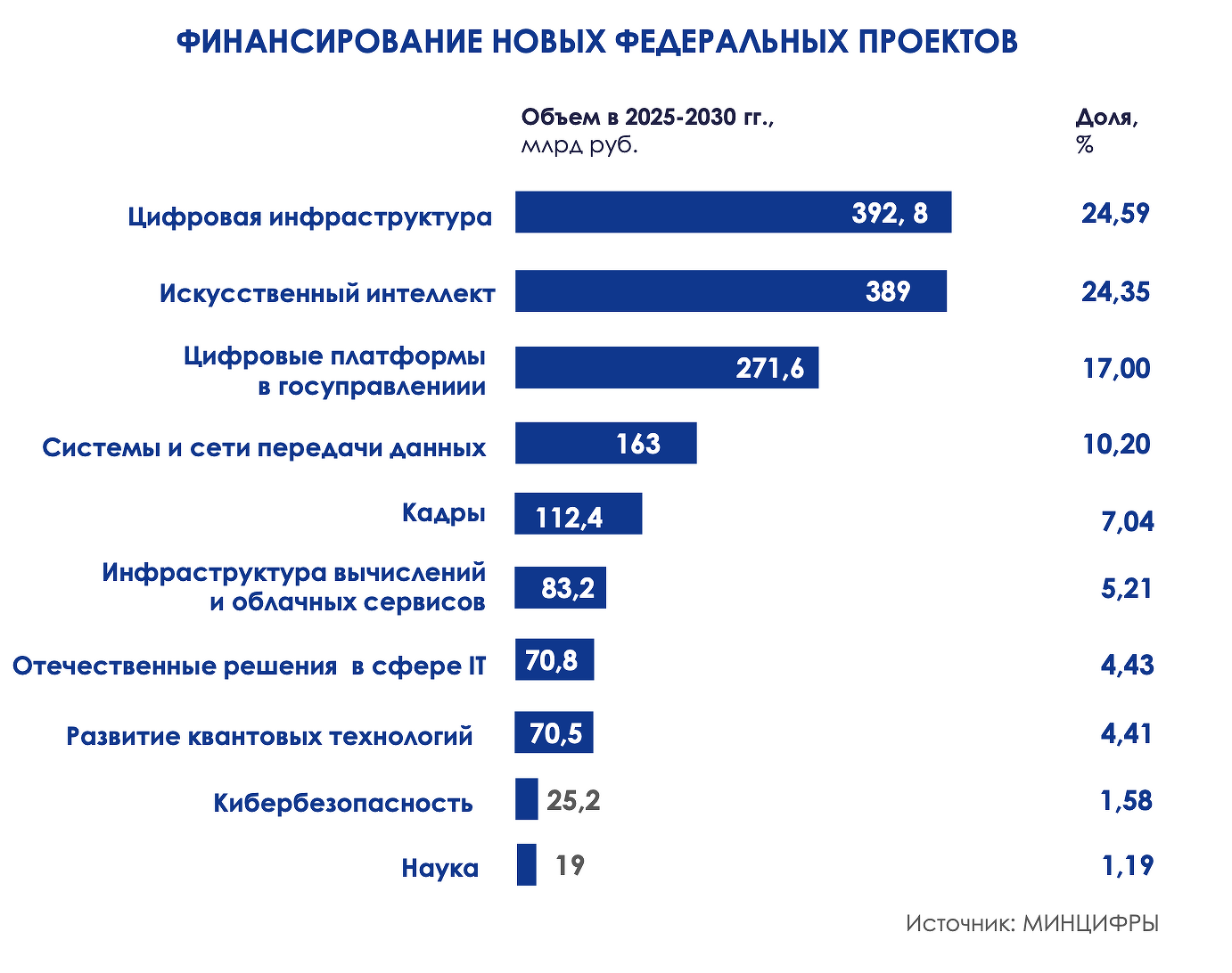
Самыми дорогими мероприятиями нового нацпроекта станут внедрение облачной платформы «Гостех» (142 млрд руб.), создание цифровой инфраструктуры образовательных учреждений (129 млрд руб.), развитие группировки спутниковой связи ГПКС (80 млрд руб.) и платформы «Госуслуги» (78 млрд руб.). Распределять финансирование планируется путем выделения субсидий (55% от общего объема средств), заключения контрактов, межбюджетных трансфертов (от Минздрава, Минпросвещения, Минтранса и других ведомств) и предоставления грантов и льготных кредитов.
По мнению Глеба Шуклина, главная угроза реализации проекта — недостаточное финансирование. 700 млрд — это меньше, чем было запланировано для национального проекта «Цифровая экономика» в период с 2019 по 2024 год — 731 млрд рублей. Плюс инфляция, рост цен. В странах сравнимых расходов на развитие экономики данных, таких как Южная Корея, Казахстан, фокус направлен непосредственно на технологии, связанные с данными, в то время как «Экономика данных» содержит и запуск новых группировок спутников, и развитие отечественной микроэлектроники, и обеспечение городской безопасности, и экологический мониторинг, и развитие здравоохранения, науки и многое другое.
Технологии для работы с данными
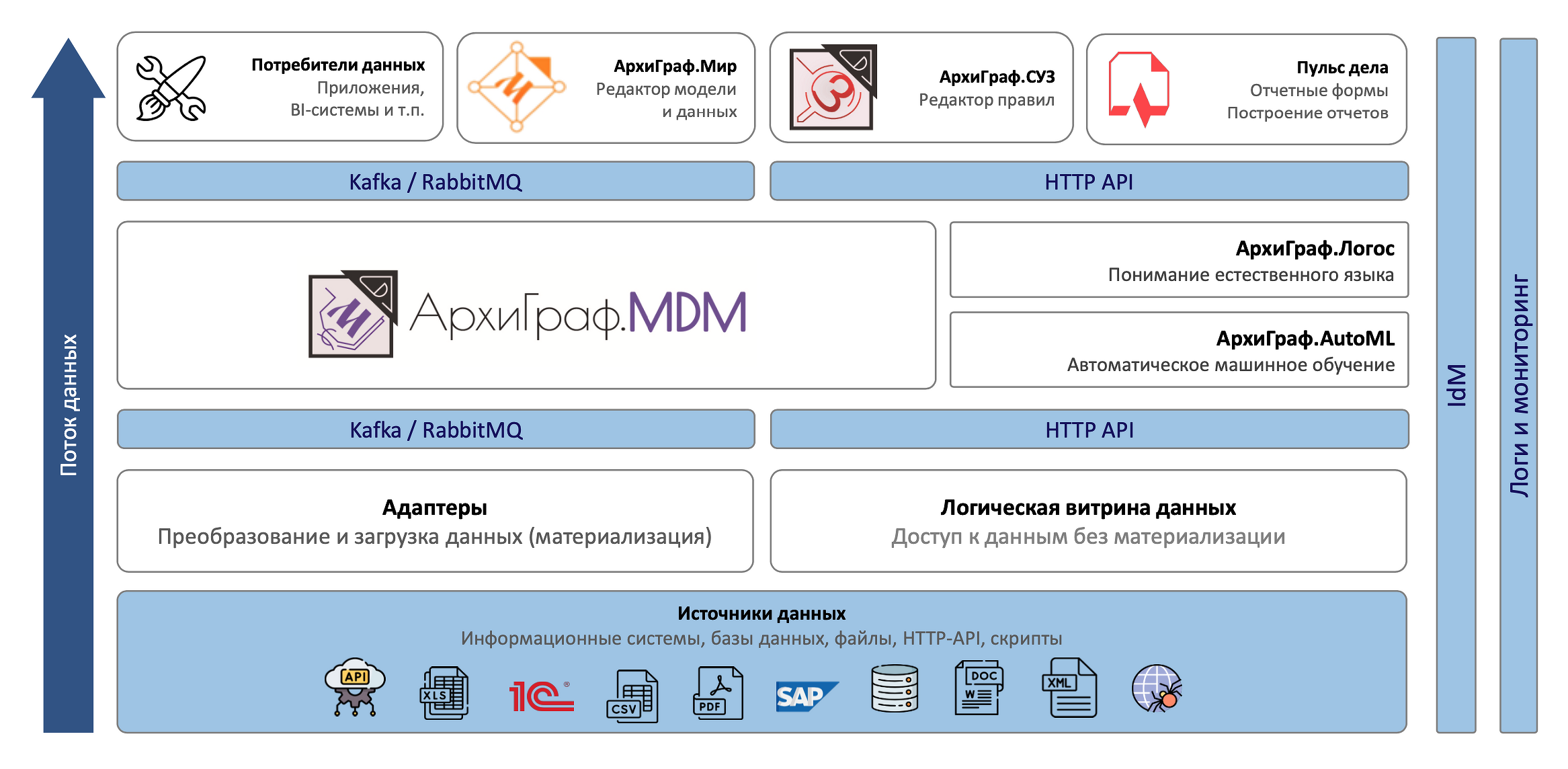
Константин Кондратьев, директор «ТриниДата», рассказал о платформе «АрхиГраф». «АрхиГраф» — это платформа виртуализации данных, предназначенная для создания корпоративного графа знаний и использования в качестве ядра дата-центрических ИТ-архитектур. Данные могут быть любые, в том числе человеческая речь в виде документов или голосовых сообщений. Компоненты платформы «АрхиГраф» на начальном этапе перехода к дата-центрической архитектуре могут выполнять функции классической MDM-системы.
На настоящий момент под управлением модели находит более 7 млн объектов. Их обновление из внешних источников осуществляется раз в сутки.
Компоненты платформы «АрхиГраф»
Максим Ковалевский, менеджер проектов «Рольф Тех», рассказал, что РОЛЬФ приступил к масштабной цифровой трансформации. Проектный офис трансформировался в продуктовый. Одним из крупнейших проектов стала замена ERP системы на базе Oracle на импортонезависимое решение собственной разработки на базе микросервисов. А при внедрении MDM-системы «Рольф» совместно с технологическим партнёром «Тринидата» развернул онтологическую платформу «АрхиГраф».
 Глеб Шуклин, руководитель стратегических проектов Ассоциации больших данных: Главная угроза реализации проекта «Экономика данных» — недостаточное финансирование
Глеб Шуклин, руководитель стратегических проектов Ассоциации больших данных: Главная угроза реализации проекта «Экономика данных» — недостаточное финансирование
 Константин Кондратьев, директор «ТриниДата»: «АрхиГраф» на начальном этапе перехода к дата-центрической архитектуре могут выполнять функции классической MDM-системы
Константин Кондратьев, директор «ТриниДата»: «АрхиГраф» на начальном этапе перехода к дата-центрической архитектуре могут выполнять функции классической MDM-системы
 Алена Беглер, аналитик «ТриниДата»: Онтологические модели позволяют не менять входные данные, а просто обращаться к ним через адаптер
Алена Беглер, аналитик «ТриниДата»: Онтологические модели позволяют не менять входные данные, а просто обращаться к ним через адаптер
 Владимир Озеров, генеральный директор CedrusData: Необходимо отделить хранилища данных от вычислительных мощностей
Владимир Озеров, генеральный директор CedrusData: Необходимо отделить хранилища данных от вычислительных мощностей
 Ольга Ведерникова, генеральный директор Epsilon Metrics: Геоданные есть у многих компаний, но они изолированы в отдельных базах данных
Ольга Ведерникова, генеральный директор Epsilon Metrics: Геоданные есть у многих компаний, но они изолированы в отдельных базах данных
 Александр Петряков, главный инженер по разработке «Сбер»: Фабрика данных «Сбера» состоит из более чем 10 тыс. серверов
Александр Петряков, главный инженер по разработке «Сбер»: Фабрика данных «Сбера» состоит из более чем 10 тыс. серверов
 Сергей Иванов, управляющий директор по корпоративной архитектуре и управления данными группы «Ренессанс Страхование»: На фоне дефицита кадров трендом последнего времени стало использование генеративного искусственного интеллекта
Сергей Иванов, управляющий директор по корпоративной архитектуре и управления данными группы «Ренессанс Страхование»: На фоне дефицита кадров трендом последнего времени стало использование генеративного искусственного интеллекта
 Михаил Кортунов, руководитель Центра больших данных инновационного центра «Безопасный транспорт»: Платформа на основании данных видеокамер определяет местоположение автомобиля и отправляет водителю информацию о событиях на дороге в режиме реального времени
Михаил Кортунов, руководитель Центра больших данных инновационного центра «Безопасный транспорт»: Платформа на основании данных видеокамер определяет местоположение автомобиля и отправляет водителю информацию о событиях на дороге в режиме реального времени

По словам Алены Беглер, аналитика «ТриниДата», онтологические модели позволяют не менять входные данные, а просто обращаться к ним через адаптер. В качестве примера она рассказала, как можно смоделировать автомобиль.
Shared-nothing системы не отвечают современным требованиям масштабируемости и производительности, уверен Владимир Озеров, генеральный директор CedrusData. Необходимо отделить хранилища данных от вычислительных мощностей. Это позволяет организовать гибридную аналитическую инфраструктуру. Важный тренд — создание Lakehouse, объединяющих озеро данных — репозитория для хранения больших объемов данных в их исходном, необработанном формате, и хранилища данных — репозитория, в котором хранятся структурированные и полуструктурированные данные из различных источников для анализа и формирования отчетов. Кроем того, активно развивается Small data — технология локальной обработки данных.
Оптимизация на примере кэширования
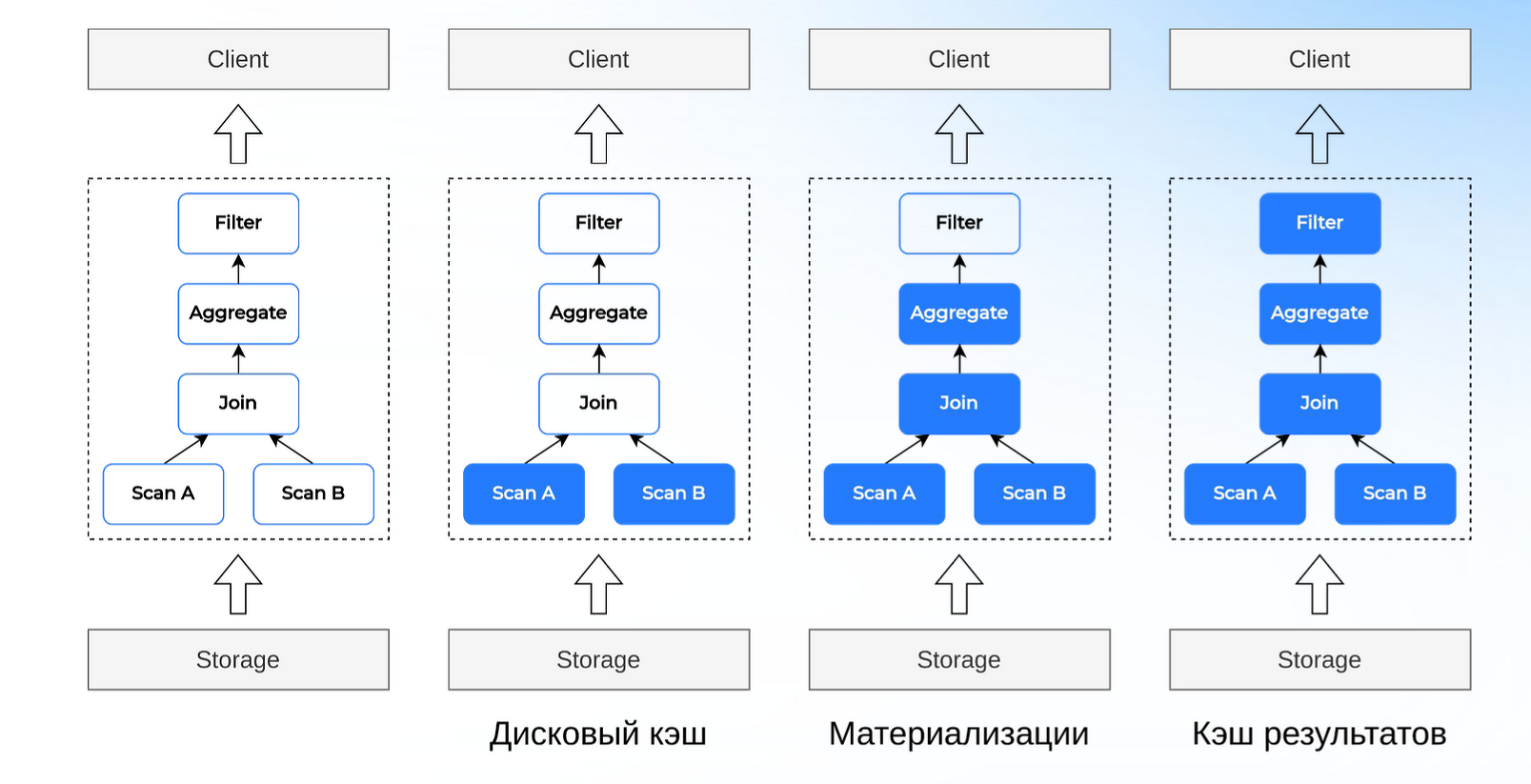
По словам Владимира Озерова, в России эти тренды становятся все более востребованы. Однако специфика нашей страны в том, что российские технологии пока уступают западным. Поэтому крупный бизнес начал самостоятельно разрабатывать решения на базе Open Source продуктов. При этом при создании форка речь часто не идет о переработке ядра. Поэтому на рынке появляется много плохих версий одного и того же продукта.
Владимир Озеров уверен, что значительно выгоднее заплатить российскому вендору, который переработает ядро и со временем создаст по-настоящему хороший продукт. В качестве примера он привел CedrusData — набор технологий для современных аналитических платформ на основе OS-продуктов.
Ольга Ведерникова, генеральный директор Epsilon Metrics, рассказала об использовании облачных решений в пространственном анализе больших данных. Ее компания занимается анализом геоданных. Ольга Ведерникова привела примеры задач, которые можно решить таким способом. Например, поиск лучших мест для новых магазинов и прогноз выручки, оптимизация покрытия сотовой связи, оптимизация маршрутов доставки.
Геоданные есть у многих компаний, но они изолированы в отдельных базах данных. Поэтому при создании геоаналитической платформы Epsilon Metrics ориентировалась на облачные решения. Хранилище данных и вычислительные мощности отделены друг от друга. Это дает возможность подключиться к облачному хранилищу и больше не перемещать данные между разными файлами, базами и хранилищами. Их можно сохранить один раз, и затем использовать в разных сервисах и комбинировать с другими данными.
Разделение вычислений и хранения
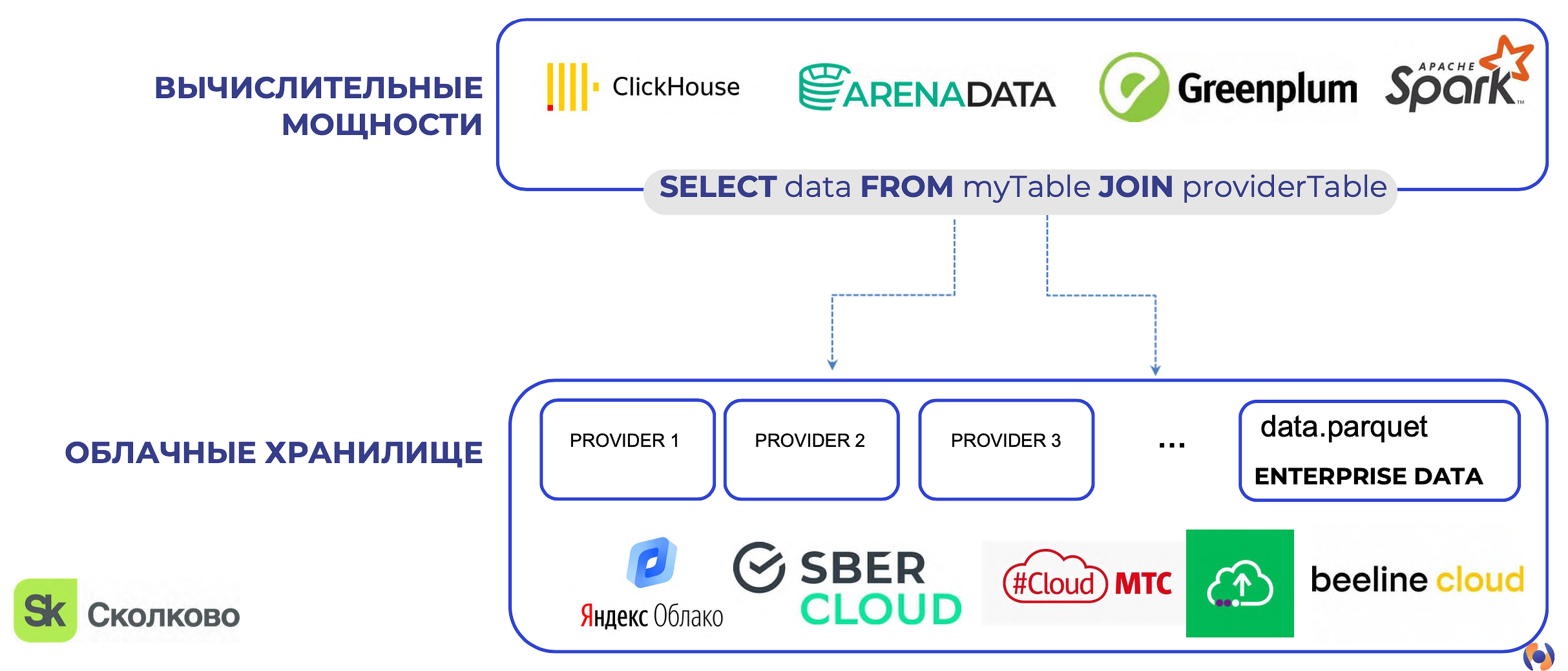
Решение поддерживает GeoParket. Используются пространственные индексы. В решении реализованы low-code инструменты, в частности, конструктор work-flow, где можно путем перетаскивания создавать пространственные SQL-запросы.
Фабрика данных «Сбера» состоит из более чем 10 тыс. серверов, рассказал Александр Петряков, главный инженер по разработке «Сбер». Он рассказал о том, как компания решала задачу сетевой изоляции. После анализа представленных на рынке продуктов было решено заняться разработкой собственного — Sber Smart Perimeter. Оно обеспечивает управление сетью HostBased Firewall, сбор телеметрии, интеграцию с учетными системами и динамическую конфигурацию. На кластере устанавливается агент SDP SP.
Схема работы агента SDP SP
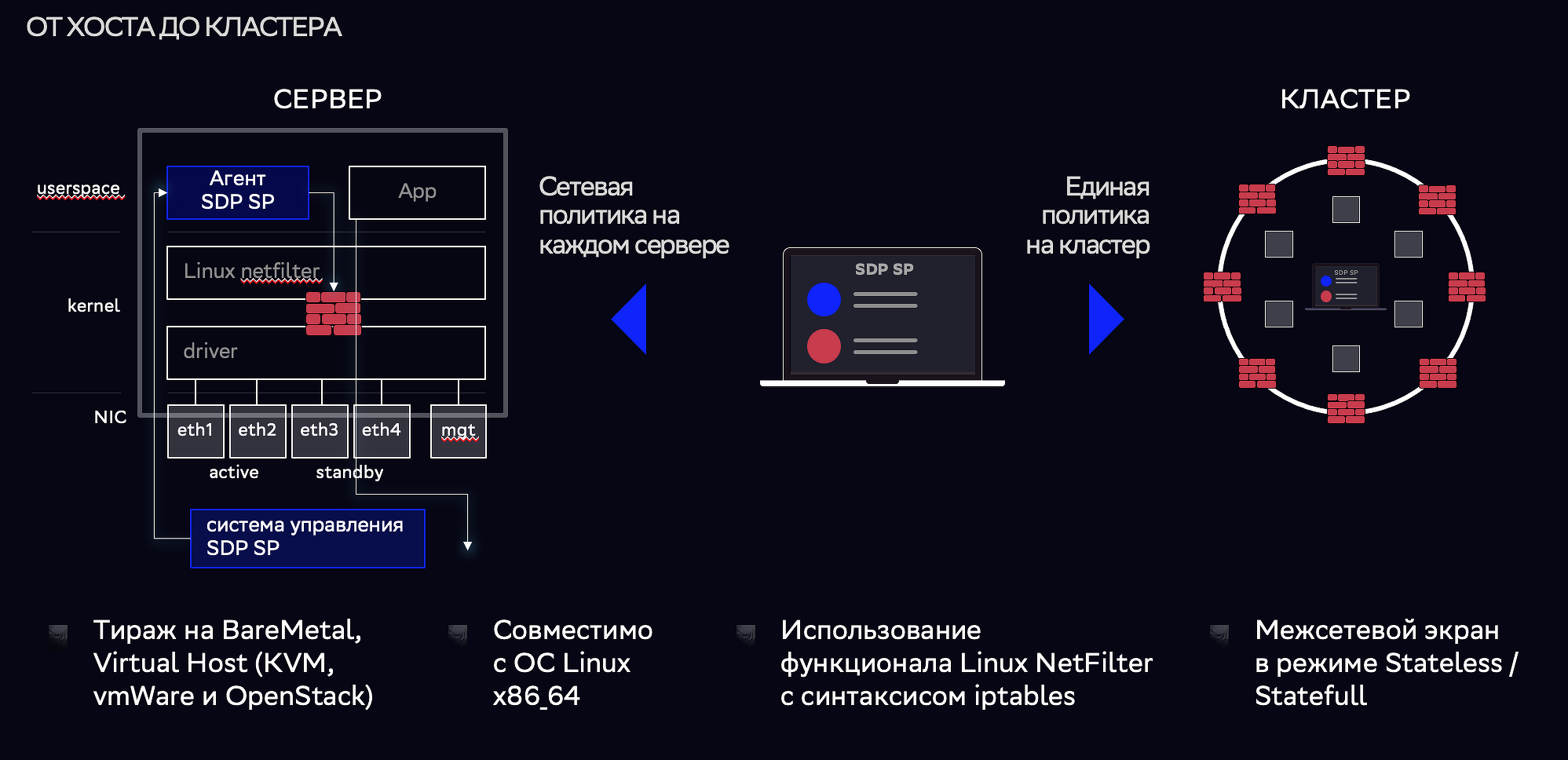
В ближайших планах — использование искусственного интеллекта, интеграция с GigaChat и с современным оборудованием.
На фоне дефицита кадров трендом последнего времени стало использование генеративного искусственного интеллекта. Он позволяет начинающим разработчикам работать значительно эффективнее, говорит модератор конференции Сергей Иванов, управляющий директор по корпоративной архитектуре и управления данными группы «Ренессанс Страхование». Кроме того, его использование дает возможность значительно упростить пользовательский интерфейс.
Генеративный ИИ также становится важным инструментом работы с данными — он способен обрабатывать голосовые запросы и используется при построении аналитики, загрузке, проектировании, создании каталогов и глоссариев данных, а также для повышения их доступности и качества.
Большие данные на транспорте
Михаил Кортунов, руководитель Центра больших данных инновационного центра «Безопасный транспорт», рассказал, что задачи его организации — информационно-аналитическая поддержка принятия управленческих решений руководством Москвы и создание удобной и безопасной среды для передвижения жителей города. Компания работает с обезличенными данными, и по результатам их анализа вносит предложения по улучшению транспортной ситуации в столице. В качестве источника информации используются данные телеметрии общественного транспорта и данные с видеокамер.
Компанией создана платформа «Космос», с помощью которой производится автоматическая рассылка, которая информирует жителей города о ключевых событиях, изменениях маршрутов, новых сервисах и способах оплаты. Также платформа на основании данных видеокамер определяет местоположение автомобиля и отправляет водителю информацию о событиях на дороге в режиме реального времени. «В нашей базе данных более 17 млн контактов, мы имеем возможность сегментировать их по полу, возрасту, району проживания, интересам, виде транспорта, частоте и маршрутам поездок и так далее», — говорит Михаил Кортунов.
В ближайшее время центр «Безопасный транспорт» намерен реализовать еще несколько сценариев. В их числе предупреждение водителей о большом количестве нарушений скоростного режима за время поездки, предложение новых маршрутов на основе данных о местоположении автомобилиста в настоящем времени, рассылка сообщений об эвакуации автомобиля.
Как организовать миграцию данных
Марина Гудимова, ведущий аналитик «Концепт Разработка», поделилась кейсом «Как мигрировать 100500 пользовательских объектов из старого хранилища в новое и остаться в живых». Она подробно рассказала, как был организован процесс переноса объектов из старого хранилища в новое.
Подход к миграции
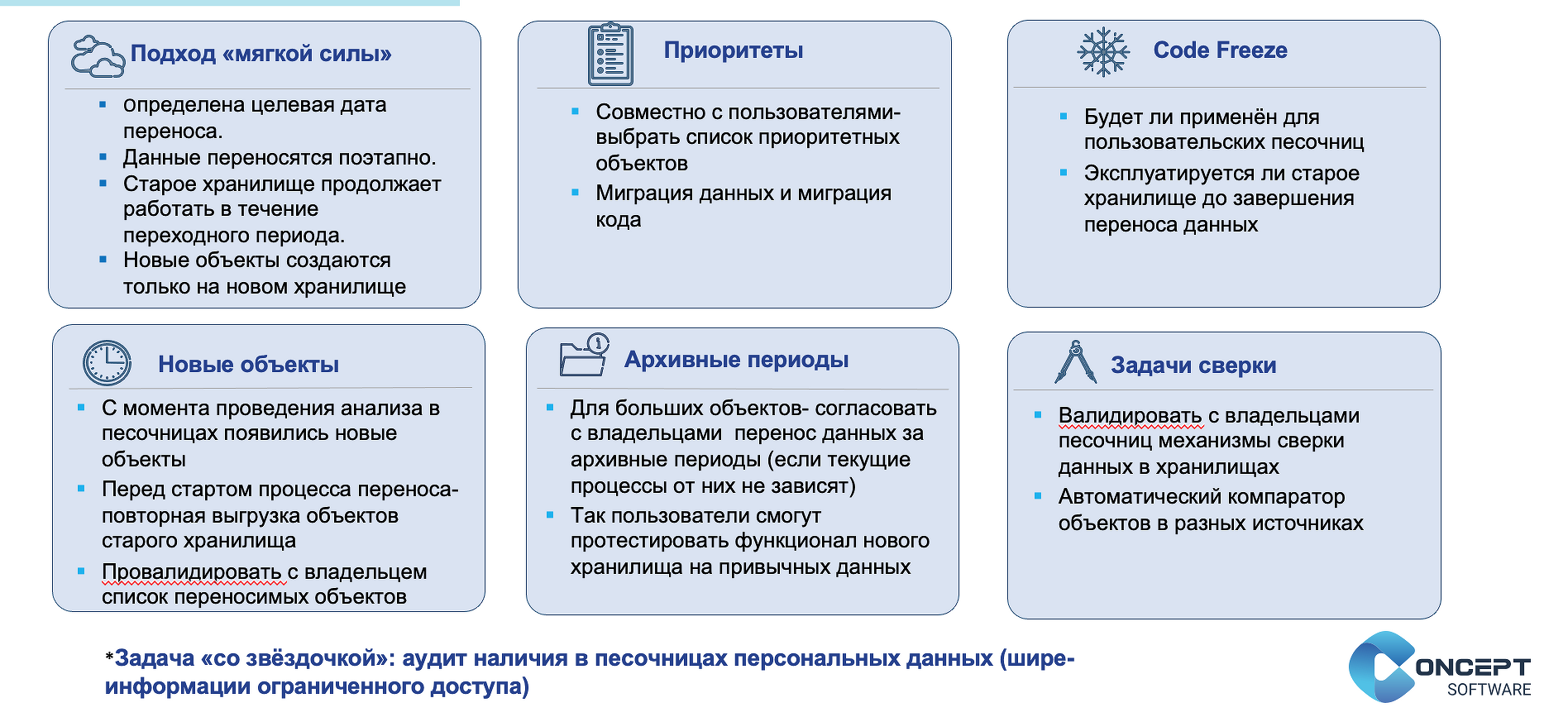
Марина Гудимова поделилась опытом, который позволит избежать ошибок. Так, она рекомендовала предварительно обследовать общедоступную разделяемую песочницу в компании, провести анализ определения принадлежности объектов конкретным подразделениям и определить подход к переносу таких объектов. При переносе данных важно не ограничиваться семплом данных для анализа, выгрузить из словаря данных все используемые типы для последующей автоматизации. При разработке автоматизированного решения лучше задавать параметрами поле партиционирования и размер переносимой партиции.
«Миграция — это возможность трансформировать работу с данными», — продолжил тему Николай Шевцов, CDO ОТП Банка. Надо не просто менять решение, а трансформировать бизнес-процессы и подумать, как встроить в них имеющиеся данные. Долгое время его банк использовал технологии Oracle Exadata, Tableau, Informatica. При выборе альтернативы было решено отказаться пользовательской песочницы и некоторых других возможностей. В конечном итоге выбор пал на решения Greenplum, ArenaData, SuperSet и пр.
Создание нового хранилища данных строилось по принципу Datamesh. Framework был разработан собственными силами. Новая платформа была интегрирована с уже существующими хранилищами и платформами банка, а процессы Data Government встроены в жизненный цикл разработки.
Сервисы на базе больших данных
Московская биржа — это, по сути, инфраструктура финансового рынка, говорит Анджей Аршавский, управляющий директор по монетизации данных Московской биржи. Через нее ежегодно проходит около квадриллиона рублей. Через биржу покупаются и продаются акции, облигации, деньги. Имеющиеся у Московской биржи данные делятся на три группы — сырые данные, производные данные и инфо-сервисы. Традиционно биржа продавала сырые данные. Но теперь решила запустить на их основе сервисы.
Так, в конце 2023 г. появился информационно-торговый терминал «Трейд Радар». Запущен маркетплейс DataShop — единая точка доступа к финансовым данным и дата-продуктам биржи. Algopack предоставляет доступ к большому набору исторических и онлайн данных рынка и аналитические возможности для алгоритмической торговли. Investor Pro — это набор аналитических сервисов для опытных инвесторов. Compliance Tool — это датасеты и сервисы для комплайенс-подразделений.
 Марина Гудимова, ведущий аналитик «Концепт Разработка»: Как мигрировать 100500 пользовательских объектов из старого хранилища в новое и остаться в живых
Марина Гудимова, ведущий аналитик «Концепт Разработка»: Как мигрировать 100500 пользовательских объектов из старого хранилища в новое и остаться в живых
 Николай Шевцов, CDO ОТП Банка: Миграция — это возможность трансформировать работу с данными
Николай Шевцов, CDO ОТП Банка: Миграция — это возможность трансформировать работу с данными
 Анджей Аршавский, управляющий директор по монетизации данных Московской биржи: Московская биржа — это, по сути, инфраструктура финансового рынка
Анджей Аршавский, управляющий директор по монетизации данных Московской биржи: Московская биржа — это, по сути, инфраструктура финансового рынка
 Владимир Колчин, главный специалист по управлению техническими данными компании «Сахалинская энергия»: Инструменты бизнес-аналитики помогают объединить данные из разных областей и представить их в удобном формате для анализа
Владимир Колчин, главный специалист по управлению техническими данными компании «Сахалинская энергия»: Инструменты бизнес-аналитики помогают объединить данные из разных областей и представить их в удобном формате для анализа
 Андрей Ильин, главный эксперт по технологиями «Сбер»: Клиент не хочет думать об инфраструктурной составляющей – он хочет видеть на своем кластере таблицы и не думать ни о чем другом
Андрей Ильин, главный эксперт по технологиями «Сбер»: Клиент не хочет думать об инфраструктурной составляющей – он хочет видеть на своем кластере таблицы и не думать ни о чем другом
 Андрей Тютякин, главный инженер по разработке «Сбер»: За 1,5 года после запуска решения число его подписчиков выросло в 2 раза
Андрей Тютякин, главный инженер по разработке «Сбер»: За 1,5 года после запуска решения число его подписчиков выросло в 2 раза
 Елена Звонарева, замруководителя Центра компетенций РФ по цифровой трансформации строительной отрасли, советник министра строительства и ЖКХ РФ: Сопротивление цифровизации в строительной отрасли достаточно большое. Но строить прогнозы, не опираясь на данные, невозможно
Елена Звонарева, замруководителя Центра компетенций РФ по цифровой трансформации строительной отрасли, советник министра строительства и ЖКХ РФ: Сопротивление цифровизации в строительной отрасли достаточно большое. Но строить прогнозы, не опираясь на данные, невозможно
 Денис Александров, дата-инженер управления по работе с данными Аналитического центра при Правительстве РФ: Специалисты Аналитического центра при Правительстве РФ проводят анализ социально-экономического развития России, ведут мониторинг достижения национальных целей развития, готовят информационно-аналитические доклады и прогнозы
Денис Александров, дата-инженер управления по работе с данными Аналитического центра при Правительстве РФ: Специалисты Аналитического центра при Правительстве РФ проводят анализ социально-экономического развития России, ведут мониторинг достижения национальных целей развития, готовят информационно-аналитические доклады и прогнозы
 Евгений Линник, руководитель офиса по анализу и управлению данными Российского футбольного союза: Решений, поддерживающих расстановку людей на футбольном поле, явно не хватает
Евгений Линник, руководитель офиса по анализу и управлению данными Российского футбольного союза: Решений, поддерживающих расстановку людей на футбольном поле, явно не хватает
 Артем Небольсин, руководитель направления HR-аналитики X5: Каждое направление в X5 взаимодействует или непосредственно с большими данными, или с продуктами на их основе
Артем Небольсин, руководитель направления HR-аналитики X5: Каждое направление в X5 взаимодействует или непосредственно с большими данными, или с продуктами на их основе
Владимир Колчин, главный специалист по управлению техническими данными компании «Сахалинская энергия», рассказал, что в сфере энергетики инструменты бизнес-аналитики помогают отслеживать и анализировать работу оборудования, в том числе, и в реальном времени. BI-инструменты также предоставляют возможность создавать отчеты на основе ключевых показателей эффективности и визуализировать данные для более наглядного анализа.
Они используются для прогнозирования и оптимизации добычи, автоматизируют процесс создания инфографики и отчетов по данным из источников. Также инструменты бизнес-аналитики помогают объединить данные из разных областей (например, геология, производство, петрофизика, лабораторные химические анализы) и представить их в удобном формате для анализа.
Владимир Колчин привел несколько примеров решений — цифровая книга скважин, система контроля специальных поглощающих скважин, система контроля поддержания пластовых давлений.
Еще недавно в «Сбере» существовала проблема с доставкой данных пользователям, рассказал Андрей Ильин, главный эксперт по технологиями «Сбер». Процесс копирования метаданных между кластерами был достаточно сложный, а копирование прав доступа к объектам Hive между кластерами происходило вручную. Доступ к репликам данных был односторонний. А если требовалось передать данные в защищенном виде, надо было дорабатывать приложения на каждом кластере.
Существовало большое количество копий данных. Их сложно было копировать между различными стеками, например, из Hadoop в Greenplum. «Но клиент не хочет думать об инфраструктурной составляющей – он хочет видеть на своем кластере таблицы и не думать ни о чем другом», — говорит Андрей Ильин.
Архитектура HDP-HDP, OZONE-HDP, GP-HDP
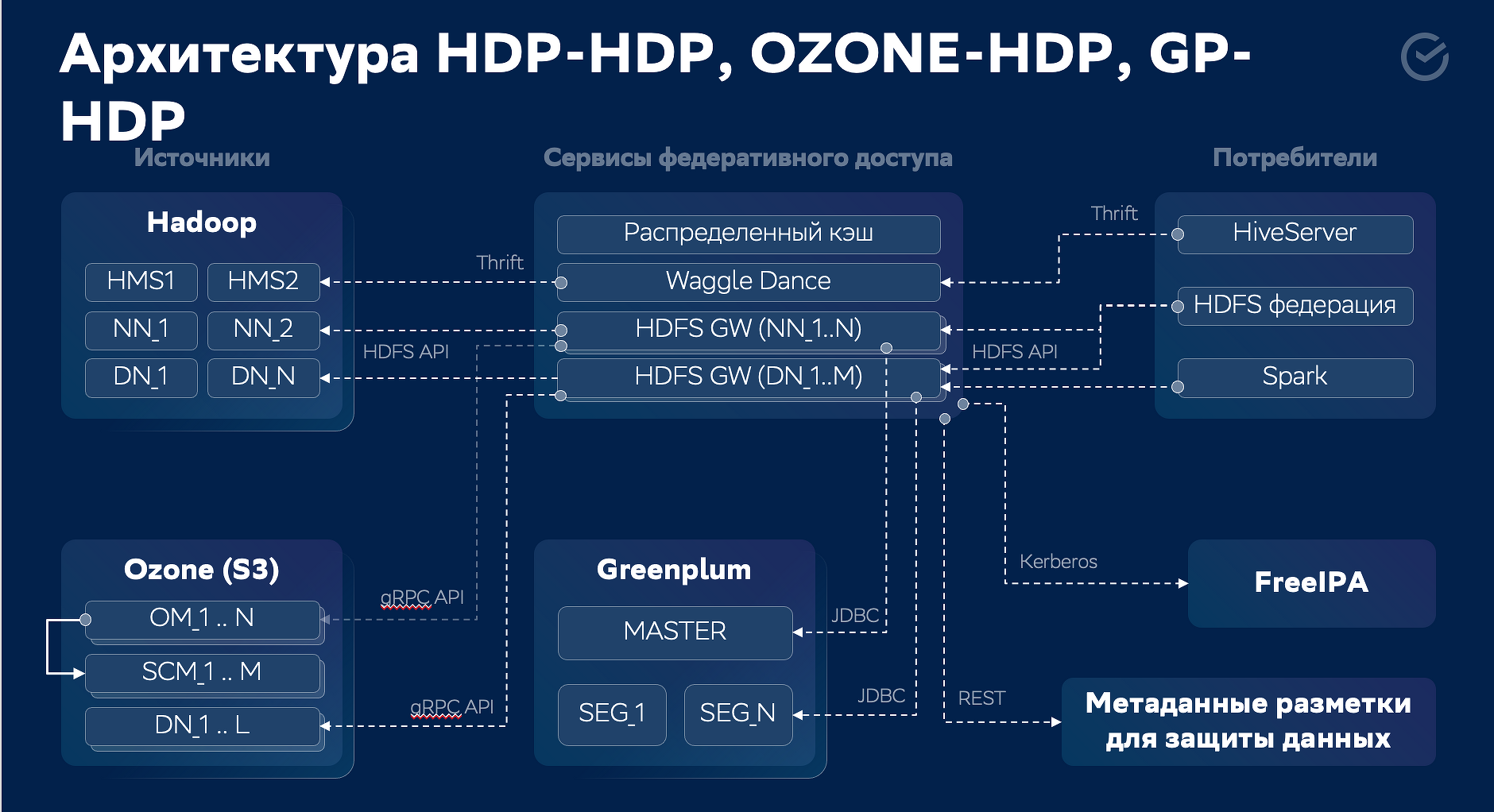
В ответ на это в «Сбере» создали новую архитектуру обмена данными между Hadoop, Greenplum, Ozone, PostgreSQL. Андрей Тютякин, главный инженер по разработке «Сбер», рассказал, с какими вызовами разработчики столкнулись в ходе реализации проекта. За 1,5 года после запуска решения число его подписчиков выросло в два раза и приближается к 60 тыс.
В ближайших планах — сделать так, чтобы пользователи могли онлайн получать данные из Hadoop, Greenplum, Ozone и создать платформу, через которую было бы удобно подключаться к данным.
«Сопротивление цифровизации в строительной отрасли достаточно большое. Но строить прогнозы, не опираясь на данные, невозможно», — говорит Елена Звонарева, замруководителя Центра компетенций РФ по цифровой трансформации строительной отрасли, советник министра строительства и ЖКХ РФ. Она рассказала о создании информационной системы управления проектами государственного заказчика в сфере строительства (ИСУП).
Система позволяет сопровождать реализацию строительных проектов на этапе их планирования, проектирования и строительства, обеспечивающая, в том числе вести информационную модель, а также создать комплексную инфраструктуру мониторинга и аналитики этапов жизненного цикла объектов капитального строительства. В 2024 г. к ней должны быть подключены все госзаказчики регионального и 70% заказчиков муниципального уровня, вся документация должна быть переведена в электронный вид.
Главная задача РФС — продвижение сборной России по футболу. Для этого активно используются большие данные, рассказал Евгений Линник, руководитель офиса по анализу и управлению данными Российского футбольного союза (РФС). Это собственные данные, внешние данные о посетителях сайтов и систем, данные интернета вещей, например, с нательных датчиков игроков. До самого последнего времени для их анализа использовалась решение Tableau. Теперь РФС переехал на BI:SuperSet 2024.
Готовых решений, учитывающих все особенности работы РФС, не существует, поэтому в союзе существует собственный отдел разработки. «Решений, поддерживающих расстановку людей на футбольном поле, явно не хватает», — сетует Евгений Линник. Также РФС пришлось обновить поставщика данных, с помощью которого оценивается положение игроков на поле в процессе игры. Он привел несколько примеров аналитических сервисов, реализованных в РФС.
Специалисты Аналитического центра при Правительстве РФ проводят анализ социально-экономического развития России, ведут мониторинг достижения национальных целей развития, готовят информационно-аналитические доклады и прогнозы. Источниками информации служат открытые и закрытые данные, рассказал Денис Александров, дата-инженер управления по работе с данными Аналитического центра при Правительстве РФ.
Он рассказал о создании каталога данных, цель которого — обеспечить аналитиков информацией их всех доступных источников. Кроме того, были созданы аналитические цифровые продукты, такие как дашборды для оценки развития отраслей экономики, социальной сферы; решения на базе машинного обучения для обработки обращений граждан; цифровые продукты по автоматизации сравнения больших массивов данных для мониторинга развития регионов России, отраслевых исследований; витрины данных для проведения экспертно-аналитических работ. Также автоматизированы математические расчеты индикаторов для проектов мониторинга показателей национальных проектов.
В X5 накоплено около 10 петабайт данных, и на их базе реализовано множество решений, говорит Артем Небольсин, руководитель направления HR-аналитики X5. Это клиентская аналитика, аналитика для поставщиков и сотрудников, планирование спроса, оценка эффективности, а также роботизация и ИИ. «Каждое направление в X5 взаимодействует или непосредственно с большими данными, или с продуктами на их основе», — говорит он.
Артем Небольсин поделился опытом, как побудить сотрудников пользоваться большими данными. В X5 им рассказывают об имеющихся инструментах в ходе онбординга, затем предлагают пройти обучение в корпоративном университете. Для руководителей существует специальная программа обучения, какие возможности представляют им большие данные.
 Короткая ссылка
Короткая ссылка









