 Поделиться
Поделиться
Как получить экономический эффект от больших данных
Большие данные занимают все более важное место в бизнесе любой компании. И чем больше их становится, тем выше требования к решениям для их обработки. На место Data Lake приходит Lake House. Извлекать данные и создавать дашборды помогает искусственный интеллект. А у аналитиков появляется время на более творческую работу. Как получить наибольший экономический эффект от анализа больших данных, обсудили участники организованной CNews Conferences конференции «Аналитика и большие данные 2025».
Что происходит на рынке больших данных
В 2024 г. объем рынка больших данных в России составил ₽319 млрд, рассказал Глеб Шуклин, директор Ассоциации больших данных, модератор конференции. Фактический эффект на выручку от внедрения технологий больших данных в индустриях в 2024 г. выше прогнозов 2023 г. на 11%. Основная причина — расширение использования генеративного искусственного интеллекта.
Российский рынок больших данных
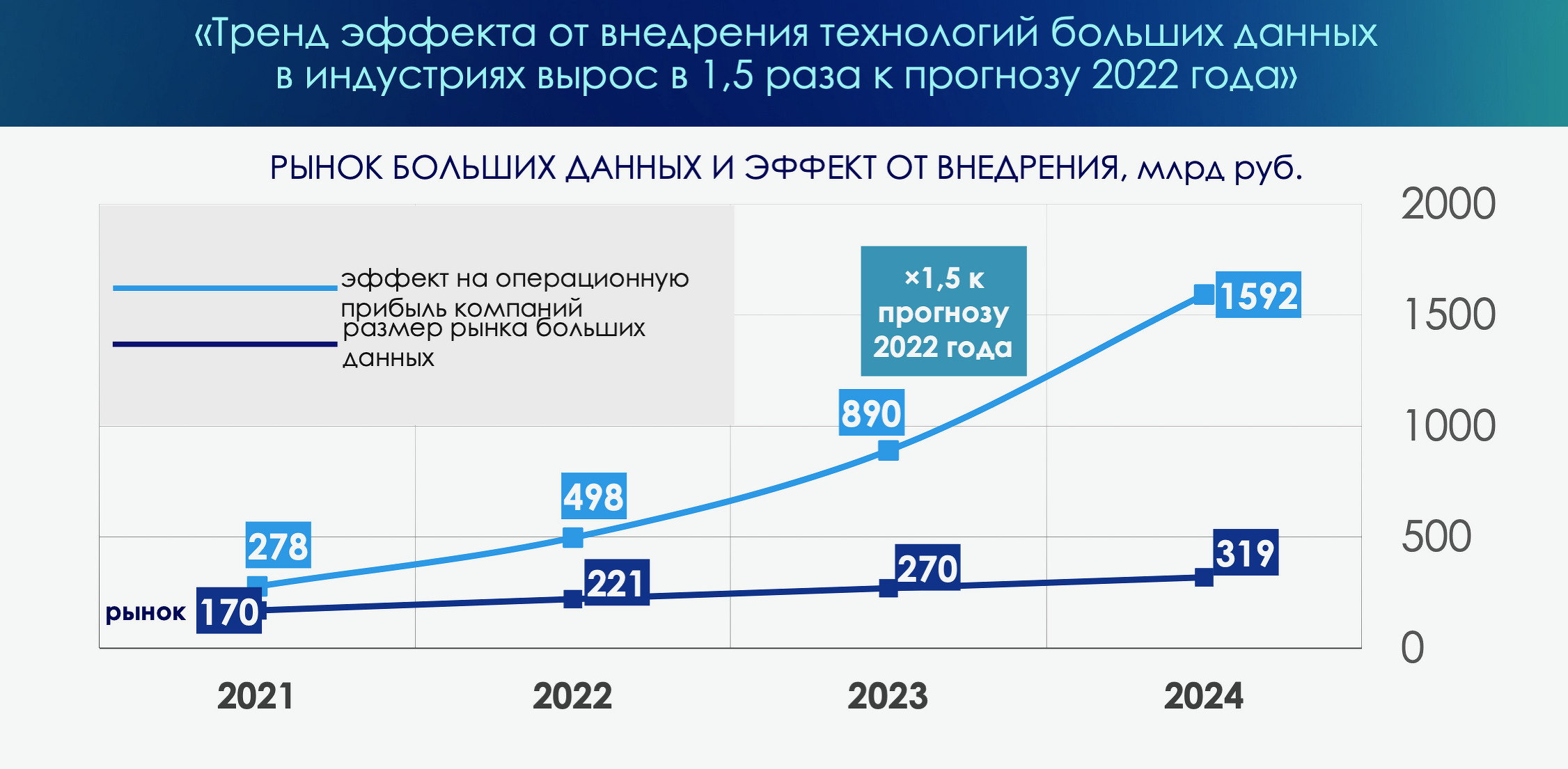
Глеб Шуклин отмечает рост объема сегмента ИТ-услуг: внедрения ПО, ИИ, заказной разработки. Кроме того, увеличились сегменты нерекламных дата-продуктов, медиа-аналитики и потребительских исследований, а также решений с использованием биометрии, OCR, компьютерного зрения. Также за счет инфляции и расходов на GPU выросли затраты на инфраструктуру.
Объемы данных неудержимо растут и достигли сотен терабайт, а иногда и петабайт. На их основе создаются десятки и сотни data-продуктов, к которым поступают сотни тысяч и миллионы SQL-запросов в день. Удовлетворить потребности рынка можно с помощью Greenplum Database, но она работает медленно и стоит недешево. «Надо, чтобы хранение данных и вычисления работали отдельно», — говорит Владимир Озеров, генеральный директор «Кверифай Лабс». Кроме того, разные вычислительные системы должны работать с одними и теми же данными. Для создания вычислительных мощностей и систем хранения существует достаточно разнообразные стек продуктов. Но кроме них понадобятся решения по обеспечению безопасности, обслуживания данных и т.д. и все они должны быть совместимы между собой.
Пример архитектуры
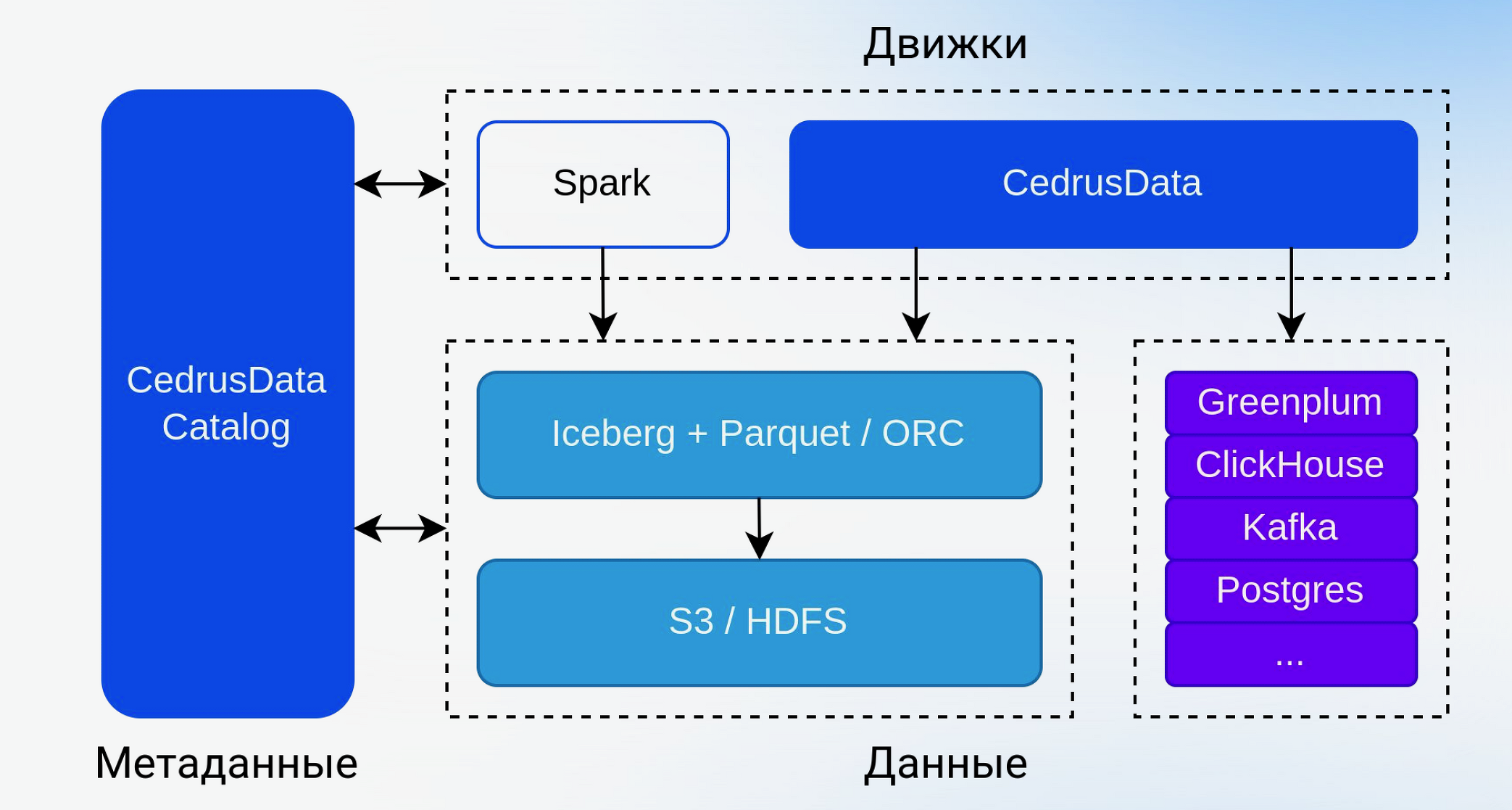
Владимир Озеров предложил в качестве альтернативы Trino использовать движок CedrusData. CedrusData содержит критические улучшения производительности на уровне ядра и отдельных коннекторов. Это позволяет системе справляться с теми же нагрузками, что и Trino, используя меньшее количество вычислительных ресурсов. Также он предложил вниманию участников конференции систему управления метаданными CedrusData Catalog. Решить проблему организации хранения данных можно с помощью решений от VK и «Закрома».
 Глеб Шуклин, директор Ассоциации больших данных, модератор конференции: Фактический эффект на выручку от внедрения технологий больших данных в индустриях в 2024 г. выше прогнозов 2023 г. на 11%
Глеб Шуклин, директор Ассоциации больших данных, модератор конференции: Фактический эффект на выручку от внедрения технологий больших данных в индустриях в 2024 г. выше прогнозов 2023 г. на 11%
 Владимир Озеров, генеральный директор «Кверифай Лабс»: Надо, чтобы хранение данных и вычисления работали отдельно
Владимир Озеров, генеральный директор «Кверифай Лабс»: Надо, чтобы хранение данных и вычисления работали отдельно
 Евгений Морозов, архитектор и соруководитель Lakehouse-платформы Data Ocean Nova, Data Sapience: Давайте разберемся, что такое Lakehouse и что должно включать в себя зрелое решение
Евгений Морозов, архитектор и соруководитель Lakehouse-платформы Data Ocean Nova, Data Sapience: Давайте разберемся, что такое Lakehouse и что должно включать в себя зрелое решение
 Максим Васильев, начальник отдела архитектуры данных Центра стратегии и инициатив, Росгосстрах: Облака и ИИ играют важную роль в развитии бизнеса, однако их использование часто запрещено политиками информационной безопасности
Максим Васильев, начальник отдела архитектуры данных Центра стратегии и инициатив, Росгосстрах: Облака и ИИ играют важную роль в развитии бизнеса, однако их использование часто запрещено политиками информационной безопасности
 Павел Денисенко, руководитель развития платформы больших данных X5: В X5 решили создать новую дата-платформу в формате LakeHouse
Павел Денисенко, руководитель развития платформы больших данных X5: В X5 решили создать новую дата-платформу в формате LakeHouse
: Надо научить владельцев данных самостоятельно вносить их в LakeHouse и дать возможность ими пользоваться") Сергей Черномырдин, руководитель направления по архитектуре данных, владелец продукта Data Lake, «Магнит» (Magnit Tech): Надо научить владельцев данных самостоятельно вносить их в LakeHouse и дать возможность ими пользоваться
Сергей Черномырдин, руководитель направления по архитектуре данных, владелец продукта Data Lake, «Магнит» (Magnit Tech): Надо научить владельцев данных самостоятельно вносить их в LakeHouse и дать возможность ими пользоваться
 Павел Коротенко, СDO «Юнилевер Русь»: Много информации не всегда означает много знаний
Павел Коротенко, СDO «Юнилевер Русь»: Много информации не всегда означает много знаний

Евгений Морозов, архитектор и соруководитель Lakehouse-платформы Data Ocean Nova, Data Sapience, предложил совместными усилиями разобраться, что такое Lakehouse и что должно включать в себя зрелое решение. LakeHouse должен поддерживать транзакции и разнообразные рабочие нагрузки, от алгоритмов машинного обучения до SQL-запросов и распределенных вычислений, обеспечивать открытость стандартизованных форматов хранения различных типов данных, возможность принудительного применения и управления схемой, гарантировать совместимость с BI, изоляцию хранения от вычислений по разным кластерам. Кроме того, для Lakehouse нужна инфраструктура S3 и Kubernetes, ее надо настроить и поддерживать. Также инфраструктурную платформу надо аттестовать в службе ИБ.
Строим дом у озера
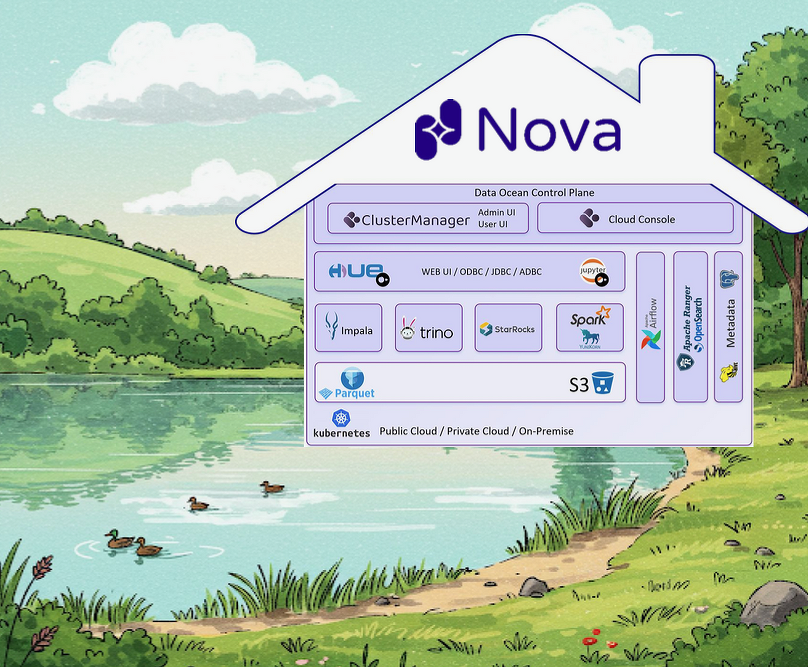
Евгений Морозов предложил использовать Data Ocean Nova — первую российскую Lakehouse-платформу данных нового поколения. Она решает комплексные задачи массивно-параллельной обработки данных. В том числе позволяет создавать и масштабировать оперативные слои в реальном времени, бесшовно работать с CRM- и ML-платформами, предоставлять федеративный доступ к базам данных и выступает в качестве универсальной аналитической платформы.
Современная архитектура данных значительно повышает эффективность принятия решений и обеспечивает четкую структуру и надежную основу для работы с данными. Это критически важно для каждой data-driven организации, уверен Николай Федоткин, технический менеджер DIS Group. Он напомнил, что сегодня ключевой инструмент для многих компаний — GenAI, но его эффективность напрямую зависит от подготовки данных, их качества и доступности. При этом исследования показывают, что для подготовки достоверных данных для ML потребуется пять и более средств управления данными.
Архитектура платформы «Селена»
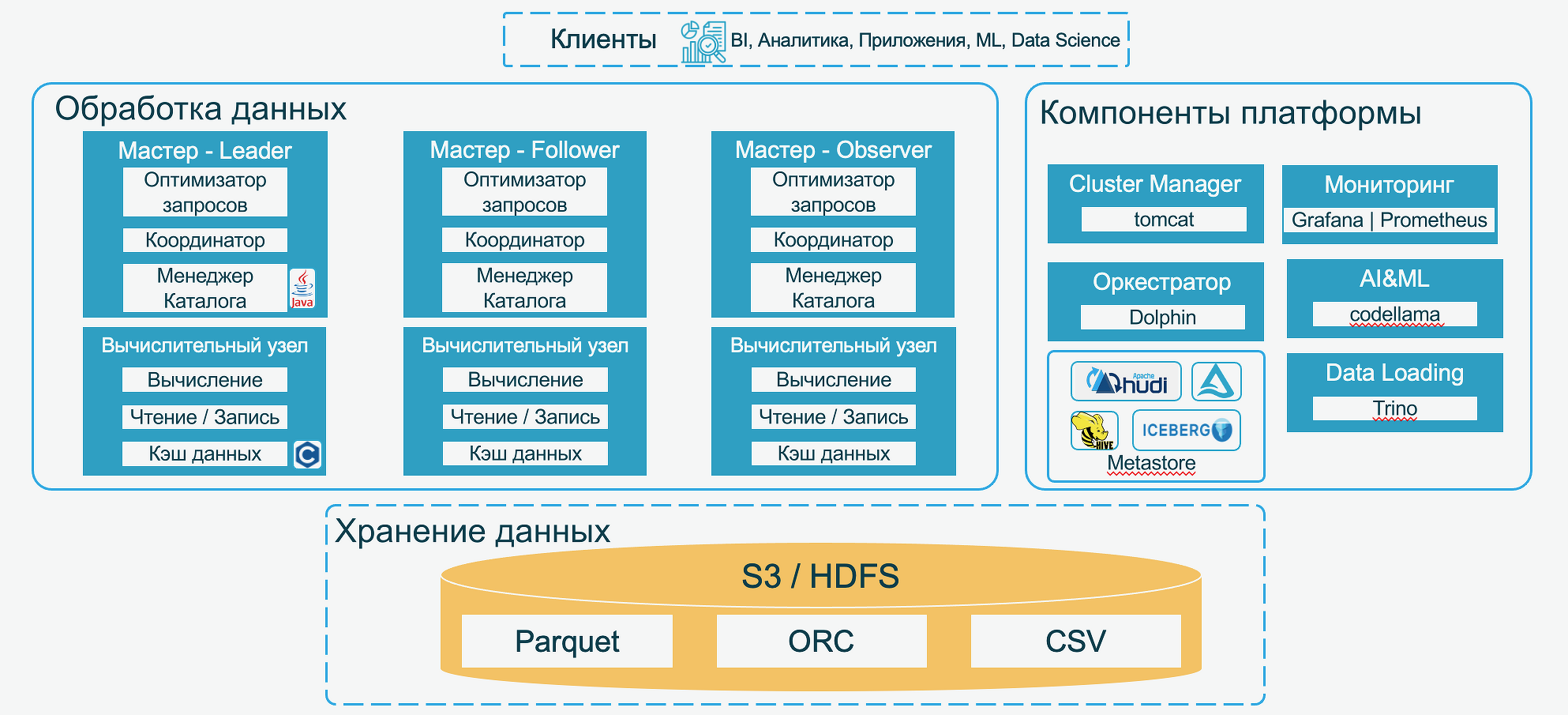
Николай Федоткин рассказал, каким должно быть решение для построения конвейера ML. Его основой должен стать корпоративный Lakehouse. Data Lakehouse объединяет структурированные и неструктурированные данные в одном хранилище, что расширяет возможности аналитики и подготовки данных для ML. Он предложил использовать аналитическую платформу «Селена». Она предназначена для работы с любыми данными любого объема и типа и обеспечивает массивно-параллельную обработку данных. В состав платформы входит объектное хранилище данных S3. При этом масштабирование уровня хранения не зависит от масштабирования уровня вычисления.
Облака и ИИ играют важную роль в развитии бизнеса, однако их использование часто запрещено политиками информационной безопасности. Требования к ИБ четко прописаны в законодательстве, однако сотрудники ИБ-службы часто руководствуются мифами, уверен Максим Васильев, начальник отдела архитектуры данных Центра стратегии и инициатив, Росгосстрах. В частности, они уверены, что локальная версия LLM безопаснее, настроить безопасную среду для LLM в облаке невозможно, взаимодействие с LLM приводит к утечке, LLM обучается на данных компании и другие клиенты могут увидеть данные бизнеса. Он привел аргументы, разоблачающие эти мифы.
«Как вариант, можно предложить службе ИБ деперсонализировать, обезличить или маркировать данные», — говорит Максим Васильев. Также можно использовать криптографические методы защиты и конфиденциальные вычисления (SMPC). В результате появится возможность обрабатывать клиентские данные без получения согласия и обеспечить их защиту от инсайдеров.
Большие данные в ритейле
X5 — это огромный сложносочиненный бизнес, который не может работать без данных. В 2016 г. для решения этой задачи было достаточно SAP HANA. Однако в 2019 г., когда в компании началось внедрение новых инструментов, в том числе на базе ИИ, была запущена новая data-платформа на базе Greenplum и Hadoop, рассказал Павел Денисенко, руководитель развития платформы больших данных X5. В 2022 г. пришлось отказаться от хранения части данных в SAP HANA и внедрить ClickHouse.
К 2024 г. перед бизнесом возникла задача научиться еще быстрее принимать решения. А для этого нужны качественные данные, причем затраты на них не должны превышать профит, полученный в результате запуска новых сервисов. В X5 решили создать новую дата-платформу в формате LakeHouse. На ней уже реализован целый ряд сервисов: оптимизация времени работы магазина на основании внешних данных о трафике и работе других объектов, Task Mining в логистике, который позволяет фиксировать поведение пользователя за компьютером до уровня элементарных действий, и Process Mining в логистике, помогающий анализировать структуру и поведение процесса на основе исторических цифровых следов его прохождения в информационных системах.
Сергей Черномырдин, руководитель направления по архитектуре данных, владелец продукта Data Lake, «Магнит» (Magnit Tech), рассказал, что в его компании платформа данных существует уже 10 лет и широко используется. Однако при ее использовании возникал целый ряд проблем. В ответ на это было принято решение создать LakeHouse и отдельное хранилище данных. На первом этапе планировалось использовать LakeHouse для решения задач аналитики, однако потом к ним добавился еще целый список бизнес-задач.
В «Магните» около 60 информационных систем, которые уже поставляют данные в текущую платформу, более 36 тыс. объектов, в том числе более 9 тыс. объектов, содержащих бизнес-данные и более 100 тыс. атрибутов объектов, содержащих бизнес-данные. Всего же в компании более 200 систем, содержащих бизнес-данные. «Мы поняли, что силами Magnit Tech решить задачу невозможно — надо научить владельцев данных самостоятельно вносить их в LakeHouse и дать возможность ими пользоваться», — рассказал Сергей Черномырдин.
На настоящий момент к LakeHouse подключено более 50 информационных систем, до конца Q2 их количество должно увеличиться до 80. Обновляется более 500 объектов данных, еще 700+ требуются для импортозамещения текущей платформы и решения задач новых проектов. Загружено более 600 ТБ данных. В ближайших планах создание коннекторов для новых типов источников, внедрение Data Contract и контроль за их исполнением, развитие интерфейсов доступа к данным в LakeHouse, хранение неструктурированных данных.
Аналитика и работа с данными переходят в разряд необходимых компетенций для многих сотрудников и руководителей. Затраты на данные и инструменты работы с ними растут, а значит, растут связанные с этим ожидания и риски. «При этом то, как мы потребляем эти данные и действуем на их основе, должно развиваться, если мы хотим раскрыть их истинный потенциал. Ведь много информации не всегда означает много знаний», — говорит Павел Коротенко, СDO «Юнилевер Русь».
По его мнению, понимание того, где какие данные есть, какие инструменты для работы с ними присутствуют в компании – шаг к переходу на другой уровень аналитики. Легкодоступные дата-продукты, решения для управления метаданными, Decision Intelligence — это не просто тренды, а необходимость в текущих условиях. «Осознанное потребление данных – это то, к чему надо стремиться», — уверен Павел Коротенко.
Александр Кулиев, директор по данным «Бургер Кинг», уверен, что переход к работе с данными является необходимым условием цифровой трансформации. Для того, чтобы внедрить Data-driven подход, в его компании создали фреймворк, описывающий единый подход к аналитике и работе с данными. Его внедрение происходило поэтапно — сначала были определены необходимые и качественные данные, затем налажены процессы управления данными, а после этого внедрены инструменты ИИ, помогающие извлекать прибыль из бизнес-процессов.
 Александр Кулиев, директор по данным «Бургер Кинг»: Переход к работе с данными является необходимым условием цифровой трансформации
Александр Кулиев, директор по данным «Бургер Кинг»: Переход к работе с данными является необходимым условием цифровой трансформации
 Владислав Филинков, руководитель платформы аналитики данных «Авито»: Сейчас около 10% дополнительной выручки и почти 15% новых клиентов «Авито» в год появляется благодаря А/В-тестированию
Владислав Филинков, руководитель платформы аналитики данных «Авито»: Сейчас около 10% дополнительной выручки и почти 15% новых клиентов «Авито» в год появляется благодаря А/В-тестированию
 Игорь Татаренко, директор департамента «Мастер Дата», Русклимат: Около половины сложных отчетов, которые делают аналитики, нужны только для «посмотреть», однако для них все равно нужны чистые и качественные данные
Игорь Татаренко, директор департамента «Мастер Дата», Русклимат: Около половины сложных отчетов, которые делают аналитики, нужны только для «посмотреть», однако для них все равно нужны чистые и качественные данные
: Что-то похожее разработал Amazon для мерчантов — сервис Amelia") Петр Лукьянченко, руководитель департамента машинного обучения ecom.tech (ранее Samokat.tech): Что-то похожее разработал Amazon для мерчантов — сервис Amelia
Петр Лукьянченко, руководитель департамента машинного обучения ecom.tech (ранее Samokat.tech): Что-то похожее разработал Amazon для мерчантов — сервис Amelia
 Леонид Боев, Data & Analytics Product Owner ИТМС: Clickhouse в 7,5 раз дешевле открывает 4519 отчетов в час по сравнении с GreenPlum
Леонид Боев, Data & Analytics Product Owner ИТМС: Clickhouse в 7,5 раз дешевле открывает 4519 отчетов в час по сравнении с GreenPlum
 Иван Корнев, ведущий аналитик «Технопарк»: Почему стоит использовать ИИ — потому что это очень дешево
Иван Корнев, ведущий аналитик «Технопарк»: Почему стоит использовать ИИ — потому что это очень дешево
 Ольга Свитнева, директор по данным ГК «Самолет»: Данные уже давно превратились в стратегический ресурс компаний и породили множество сервисов
Ольга Свитнева, директор по данным ГК «Самолет»: Данные уже давно превратились в стратегический ресурс компаний и породили множество сервисов
 Анна Богдашкина, руководитель по развитию цифрового бизнеса «Дом.РФ Технологии»: На сайте «Дом.РФ» собраны данные обо всех новостройках страны с подробной информацией
Анна Богдашкина, руководитель по развитию цифрового бизнеса «Дом.РФ Технологии»: На сайте «Дом.РФ» собраны данные обо всех новостройках страны с подробной информацией
На старте проекта команда столкнулась с рядом сложностей: отсутствие централизованной системы хранения и анализа данных, сложности масштабирования, ограниченный ресурс команды и обеспечение соответствия нормативным требованиям. Была создана Создание Data Platform, в которую вошли хранилище данных, Data Lake и ML-платформа. Александр Кулиев рассказал, как ИИ применяется в управлении ресторанами и взаимодействии с клиентами. В результате эффективность CRM и каналов продаж выросла на 3-6% по различным направлениям за счет моделей персонализации и автоматизации процессов. Первые тесты в ресторанной части бизнеса повысили эффективность бизнес-процессов на 6%.
В 2016 г. «Авито» решила создать свою платформу для A/B тестирования. Прототип появился в 2018 г. «Авито» всегда была data-driven компанией, поэтому нам удалось запустить более 4 тыс. тестов в год», — говорит Владислав Филинков, руководитель платформы аналитики данных «Авито». В компании разработали собственный продукт для тестирования и аналитики Trisigma. Сейчас около 10% дополнительной выручки и почти 15% новых клиентов «Авито» в год появляется благодаря А/В-тестированию.
Trisigma дает возможность освободить время аналитика на продуктовую работу. Он один раз заносит метрики в систему, затем использует их, когда необходимо, без потребности считать их руками. Метрики могут использоваться как для экспериментов, так и для BI-отчетности и ad-hoc задач.
Также в «Авито» разработали продукт для анализа и визуализации продуктовых и бизнес-метрик «М42». Он позволяет бизнесу анализировать метрики в различных сегментах без обращения к аналитикам, делает аналитику доступной без SQL и программирования. В ближайших планах расширение аналитических сценариев, упрощение работы с семантическим слоем и повышение self-service за счет ИИ.
Любая компания создает огромное количество отчетов. Однако около половины сложных отчетов, которые делают аналитики, нужны только для «посмотреть». Однако для них все равно нужны чистые и качественные данные. Для того, чтобы их получить, необходима единая мастер-система хранения данных по номенклатуре, считает Игорь Татаренко, директор департамента «Мастер Дата», Русклимат. Очень важно разработать правила ведения данных, определить обязательные и настроить автоматическую валидацию — только так можно исключить человеческий фактор. Кроме того, надо заранее планировать развитие информационных систем — ведь средний срок появления данных в системе может достигать нескольких месяцев.
У «Самоката» множество точек присутствия. Для того, чтобы они работали без сбоев, всем — и пользователям, и топ-менеджерам — необходима самая разная аналитика. Для ее подготовки аналитикам требуется много времени на выгрузку информации и подготовку отчетов. Компания решила создать ИИ-ассистента, который сможет самостоятельно формировать запросы и создавать дашборды. «Что-то похожее разработал Amazon для мерчантов — сервис Amelia», — рассказал Петр Лукьянченко, руководитель департамента машинного обучения ecom.tech (ранее Samokat.tech).
Он рассказал, как разрабатывался сервис на базе LLM-модели. В результате появился бот, которому можно задать простые вопросы, например, какой товар лучше всего продавался на прошлой неделе. Также бот поможет со статистическими данными, даст необходимые ссылки. Отдельная задача — научить бота реагировать на нерелевантные вопросы. По мнению Петра Лукьянченко, умный бот может быть полезен везде, где есть данные.
До 2022 г. для визуализации отчетности в ИТМС использовали Snowflake и Power BI из облака Microsoft Azure, рассказал Леонид Боев, Data & Analytics Product Owner ИТМС. Потом компания решила мигрировать в облако Yandex.Cloud на GreenPlum и BI DataLenz. Оказалось, что время загрузки отчета составляет 4-6 мин, а GreenPlum очень дорого масштабировать.
Было принято решение разделить процессы расчета и предоставления данных. На тестовом стенде запустили GreenPlum и ClickHouse и провели нагрузочное тестирование. В результате оказалось, что Clickhouse в 7,5 раз дешевле открывает 4519 отчетов в час по сравнении с GreenPlum (параллельно открывается приблизительно 100 отчетов) и в 12 раз дешевле открывает отчеты быстрее чем за 62 секунды, по сравнению с GreenPlum. Средняя скорость открытия 70% наиболее быстро успешно открытых отчетов в Greenplum составила 62 сек.
Иван Корнев, ведущий аналитик «Технопарк», уверен, что ИИ стоит применять там, где процессы хорошо описаны, существуют рутинные, регулярно повторяющиеся задачи и задачи с высокой стоимостью специалистов. Он привел пример обработки Ad hoc-запросов с помощью ИИ-ассистента, способного делать аналитику по запросу на естественном языке. «Почему это стоит использовать — потому что это очень дешево!», — говорит Иван Корнев. Стоимость одной визуализации составляет 0,3 руб, стоимость хостинга — 1000 руб/час. При этом такой бот не сможет заменить аналитика — его цель освободить его время для решения творческих задач.
Большие данные в строительстве
Данные уже давно превратились в стратегический ресурс компаний и породили множество сервисов, напомнила Ольга Свитнева, директор по данным ГК «Самолет». При этом мир данных постоянно меняется, меняется их архитектура — теперь это LakeHouse. В ГК «Самолет» создана платформа данных. Ольга Свитнева рассказала, как она организована и какие сложности возникли при внедрении Master Data Management (MDM).
«Компании не вкладываются в MDM, потому что не видят прямой связи между управлением данными и своими ключевыми задачами», — говорит она и поделилась опытом ГК «Самолет». MDM создает единый источник данных, где информация о клиентах всегда актуальна и согласована. MDM объединяет данные из разных источников, обеспечивая полноту и точность аналитики. Единый справочники НСИ обеспечивают единые стандарты для всех систем и процессов и позволяют централизованно управлять изменениями, которые автоматически применяются во всех связанных системах.
На сайте «Дом.РФ» собраны данные обо всех новостройках страны с подробной информацией. Это первый и основной источник данных обо всех строительных проектах, говорит Анна Богдашкина, руководитель по развитию цифрового бизнеса «Дом.РФ Технологии». Эти данные используют агентства недвижимости, застройщики, банки, маркетинговые агентства, производственные предприятия, недавно стали проявлять интерес маркетплейсы.
В API ЕИСЖС входит более 100 полей с данными по каждому застройщику, жилому комплексу, объекту строительства, информация о коммерческих и нежилых помещениях, даты выдачи ключей, фотографии хода строительства, максимальное количество данных в машиночитаемом виде в формате json или xml. В ближайшее время планируется расширить список данных по объектам жилищного строительства, внедрить ID ОДС, расширить атрибутивный состав данных.
 Короткая ссылка
Короткая ссылка







