


Сегодня многие компании, масштабирующие разработку ML-решений, самостоятельно занимаются построением рабочих сред для дата-специалистов и часто на этом пути сталкиваются с неэффективным использованием вычислительных мощностей, рисками безопасности и высокой стоимостью поддержки и развития. Универсального решения для этих проблем пока не существует, однако есть компании, которые значительно продвинулись в этом направлении и готовы предложить свой опыт и наработки рынку. О том, какие подходы сегодня практикуются в построении рабочих мест для ML-команды, в чем их недостатки и риски, а также каким образом их можно снизить, CNews поговорил с Алексеем Могильниковым, директором по технологиям работы с данными в компании Rubbles, специализирующейся на разработке интеллектуальных продуктов для крупного бизнеса.
Алексей МогильниковRubbles
CNews: Алексей, расскажите коротко об опыте Rubbles в разработке ML-решений.
Алексей Могильников: Rubbles уже более девяти лет занимается созданием ML-решений для крупного бизнеса. Мы работаем с финансовым сектором, розничными сетями, промышленными предприятиями, предлагая им интеллектуальные продукты для бизнес-планирования и взаимодействия с клиентами, цифровые двойники и системы поддержки принятия решений. За это время мы реализовали более 50 масштабных ML-проектов, что позволило нарастить весьма ценную экспертизу в разработке. С каждым новым проектом мы совершенствовали практики, создавали технологические компоненты для повышения собственной эффективности и скорости разработки. В какой-то момент наши наработки в области инфраструктуры и MLOps мы стали не только использовать у себя, но и предлагать внешнему рынку, что вылилось в отдельное продуктовое направление бизнеса. Сегодня оно включает систему управления рабочими местами дата-специалистов, фреймворк для разработки пользовательских приложений, инструменты для продуктивизации аналитических моделей, прикладные ML-библиотеки, MLOps и аналитическую инфраструктуру, системы обработки и хранения данных и пр. Все эти решения объединены в технологическую платформу Rubbles Data Application Suite. В них уже заложена наша многолетняя межотраслевая экспертиза, и их совершенствование продолжается благодаря опыту и обратной связи от компаний-заказчиков, которые используют наши компоненты в построении своих рабочих сред для дата-специалистов и для развития MLOps-инфраструктуры в целом.
CNews: Как вообще устроена рабочая среда дата-специалистов в компаниях? Есть типовой пример?
Алексей Могильников: Лучше рассматривать это в общем MLOps-контексте. Все ключевые компоненты можно увидеть на этой схеме:
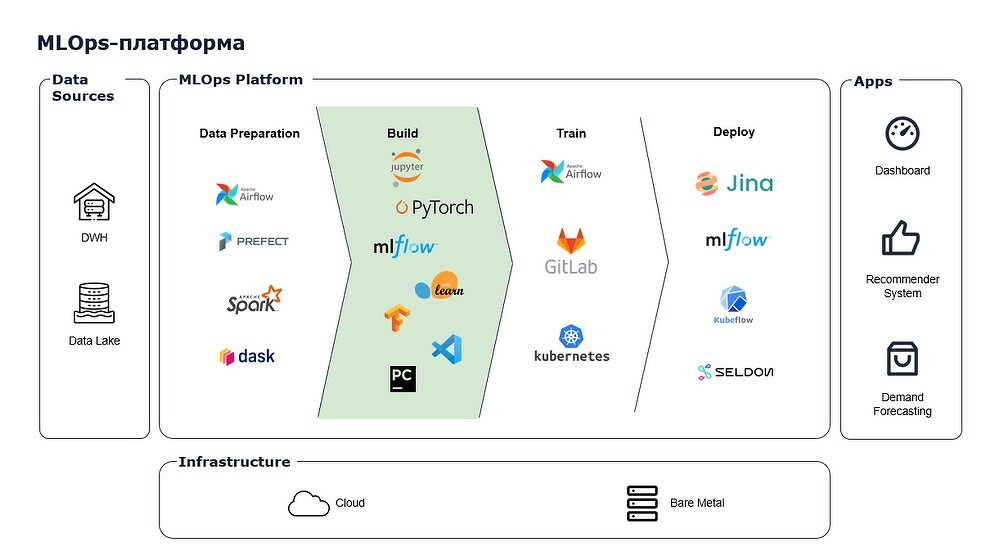
Здесь несколько блоков. Первый — это источники данных: озера и корпоративные хранилища. Далее идут блоки, которые непосредственно составляют MLOps-платформу и покрывают все стадии разработки. Сюда входят:
- компоненты для обработки данных (наиболее часто используются Airflow, Prefect, Spark, Dask);
- инструменты для подготовки моделей и экспериментов (самый популярный — JupyterLab);
- обучение и подготовка моделей для вывода в продакшн (здесь в обороте GitLab, Kubernetes, Airflow);
- поддержка уже развернутых моделей (для этого существуют Seldon Core, MLflow, Kubeflow, Jina).
Конечно, богатство рынка не ограничивается лишь теми программными продуктами, которые я перечислил, но чаще всего команды разработки строят себе рабочие среды путем комбинаций этих решений.
И последний блок — это те системы (рекомендательные, прогнозные и прочие), для которых наши ML-модели и разрабатываются.
А в основе всех этих блоков — hardware-инфраструктура, которая может быть собственная или полученная по модели PaaS (Platform-as-a-Service) или HaaS (Hardware-as-a-Service).
CNews: Какой подход практикуют компании при построении рабочих мест ML-разработчиков?
Алексей Могильников: Опишу, как чаще всего начинается этот путь. У компании появляется ML-команда, ей выделяют сервера внутри или в облаке. Если команд несколько, то сервера выделяют каждой. Первым делом специалисты обращаются к open source решениям: устанавливают себе JupyterLab, JupyterHub или Kubeflow и обычно с помощью Docker руками на каждой машине разворачивают для себя рабочее место. И далее начинается борьба с тремя ключевыми проблемами ML-разработки: нехваткой/избытком вычислительных мощностей, рисками безопасности и высокой стоимостью поддержки и развития инфраструктуры.
CNews: Каковы предпосылки возникновения этих проблем с эффективностью и безопасностью ML-разработки?
Алексей Могильников: Давайте по порядку. Первая проблема, о которой дата-специалисты не думают, но о которой думает бизнес, — это неэффективность использования вычислительных ресурсов. Она связана с двумя факторами. Первый — обычно железо выделяется на команду. Соответственно, если у нас несколько команд, то каждой — свои сервера и сопутствующая инфраструктура. Второй — нагрузка на это железо неравномерна из-за особенностей разработки: бывают достаточно длительные периоды, когда оно вообще простаивает, а бывает пиковая активность и острая нехватка мощностей. Часто возникает ситуация, что у команды А избыток мощностей, а у команды Б — нехватка, так как идут эксперименты, но они между собой не делятся вычислительными ресурсами. В результате бизнес вынужден дополнительно закупать железо для каждой команды, чтобы всем хватало. Хотя и текущих мощностей может быть достаточно, если ими правильно управлять.
Вторая проблема — безопасность. Наибольшие риски ИБ со стороны команд разработки связаны с отсутствием двух важных составляющих: контроля доступа к источникам данных и мониторинга внутри рабочего места дата-специалистов. Если доступ к системам с данными выдается сразу всем членам команды и никак не регламентируется, то эти данные могут попасть в руки людям, которые никакого отношения к этому проекту разработки не имели, или же сохраниться в руках тех, кто уже никак к проекту не относится. А отсутствие мониторинга работы с данными внутри рабочего места грозит рисками утечки и невозможностью отследить, чьи и какие действия могли к этому привести. Ведь мы не можем знать, какие преобразования данных проводил специалист и на какую флешку он их скачивал.
Ну и касательно третьей проблемы — высокой стоимости развития и поддержки — нужно отметить два момента. Первый: популярно заблуждение, что дата-специалисты знают все про DevOps и MLOps и сами могут заниматься развитием этих практик в компании, а значит тратить деньги на отдельную MLOps-команду не надо. На деле их знания в этой области чаще всего оказываются поверхностными. К тому же основная задача ML-команды — анализ данных, построение моделей и проведение экспериментов. Заниматься развитием инфраструктуры и усовершенствованием инструментария для разработки, параллельно думая о безопасности, устойчивости и производительности, им будет некогда. Следовательно, на отдельную MLOps-команду придется потратиться. Второй момент, почему стоимость поддержки высокая, — это то, что управление окружениями, в которых работают дата-специалисты, происходит в ручном режиме. Это удлиняет процесс разработки, плюс не всегда при ручном воспроизведении окружения в «проде» удается это сделать хорошо — люди иногда совершают ошибки. В результате члены одной и той же команды могут работать в разных окружениях или в «проде» оказывается не то окружение, в котором модель обучалась и подтверждалось ее качество. Как следствие, time-to-market растягивается.

CNews: Какие есть варианты решения?
Алексей Могильников: Это проблемы из разряда тех, которые решаются до бесконечности. Можно просто унести всю разработку в облако — для этого есть ML Space от «Сбера», DataSphere от Yandex, DataBricks, который работает во всех популярных западных облаках, ну и SageMaker в AWS. Однако этот вариант не подойдет компаниям со строгими правилами ИБ и чувствительными данными, которые нельзя передавать вовне. Кроме того, там тоже нет сколько-нибудь серьезных способов логировать и мониторить действия с данными внутри рабочего места, и что-либо доработать под свои требования тоже не получится. Ну и с зарубежными сервисами, как мы знаем, есть риски того, что их отключат. Плюс по законодательству в них запрещено обрабатывать персональные данные. Второй вариант — доводить до ума внутреннюю разработку on-premise на основе открытых инструментов. Здесь тоже есть свои нюансы, конечно.
CNews: В чем же заключаются эти нюансы MLOps-улучшений?
Алексей Могильников: Начнем с того, что существует два подхода, как проводить улучшения. Первый — собственными силами методом проб, ошибок и решений в стиле ad hoc. Вариант приемлем, если есть готовность выделять время и людей, чтобы писать плагины для логирования действий с данными на рабочем месте, развертывать дополнительный прокси, формировать шаблоны для воспроизведения рабочих мест, реализовывать сетевой контроль, безопасную доставку реквизитов доступа к внешним системам, придумывать способы повышения утилизации рабочих мест и прочее. В общем-то существует множество инструментов и методик, как все это сделать, и поначалу кажется, что все легко, но по факту — долго и дорого, и вообще это практически бесконечный проект. Плюс есть риск, что всю MLOps-архитектуру придется перестраивать несколько раз просто потому, что придет владелец продукта с другим видением, а через год ему на замену придет новый владелец продукта, и у него тоже окажется другое видение, как правильно. И все начнется по новой, а это трата времени и денег.
Второй вариант — получить комплекс MLOps-инструментов для решения вышеперечисленных проблем «из коробки», тем самым облегчив жизнь команде и позволив ей заниматься не «изобретением велосипеда», а реальными проектами развития.
CNews: Вы ранее сказали, что у Rubbles есть целое продуктовое направление по MLOps. Какое коробочное решение вы предлагаете в ответ на обозначенные вами вызовы и как альтернативу «изобретению велосипеда» ?
Алексей Могильников: В нашем продукте Rubbles Data Science Workspace (Rubbles DSW) уже реализованы все инструменты, с помощью которых можно закрыть те задачи в области безопасности, утилизации железа и повышения эффективности команд, которые я ранее обозначил.
В части безопасности в Rubbles DSW есть система ролей и авторизации с возможностью интеграции с корпоративной системой, а также инструменты логирования действий дата-специалистов в рабочих окружениях, чтобы отслеживать, кто к каким данным обращался и какие манипуляции с ними проводил. Плюс наше решение может быть развернуто на инфраструктуре заказчика — on-premise, что исключает риски, присущие облачным сервисам.
В плане управления нагрузкой на железо ценность решения Rubbles DSW в том, что оно работает поверх Kubernetes и нативно с ним проинтегрировано. За счет этого у нас реализована возможность по мере необходимости резервировать вычислительные мощности под рабочие места, сворачивать их автоматически, если они не используются, и проводить квотирование и бюджетирование ресурсов для команды. Это значительно повышает утилизацию железа и сокращает необходимость в инвестициях для наращивания мощностей.
Что касается повышения эффективности команд, то здесь стоит отметить две главные ценности нашего продукта. Первая — это пользовательский интерфейс, который позволяет любому дата-специалисту без компетенций в MLOps и DevOps быстро и легко развернуть себе рабочее место со всеми инфраструктурными настройками «из коробки». Вторая — это готовые шаблоны рабочих мест. Мы считаем их важнейшей сущностью Rubbles DSW, потому что они избавляют от огромного количества проблем при масштабировании ML-разработки. Дело в том, что обычно, когда нет шаблонов, дата-специалисты сами создают себе рабочие окружения — выбирают версии Jupyter, формируют наборы инструментов и так далее. В результате почти всегда в одной команде создаются разные рабочие среды, из-за чего бывают трудности с воспроизведением одних и тех же экспериментов на разных рабочих местах. Проблема нарастает вместе с ростом команд и достигает апогея в момент вывода разработки в продакшн, когда окружение должно быть стабильным для нормальной работы модели. Наличие шаблонов позволяет не допускать такого «зоопарка» в окружениях, что сокращает time-to-market.
Добавлю, что решение Rubbles Data Science Workspace совместимо со всеми популярными open source программными продуктами для ML-разработки (Jupyter, VS Code, Airflow, MLflow и прочими). К тому же мы не ограничиваем свободу заказчиков в плане кастомизации инструментария, так как понимаем их потребность и заинтересованность использовать собственные наработки и самостоятельно перестраивать решение под свои запросы. Гибкость и совместимость — главная философия всех наших продуктов для ML-разработки в рамках Rubbles Data Application Suite.
■ erid:Kra23uYYFРекламодатель: ООО «РАБЛЗ»ИНН/ОГРН: 7725806256/1137746959900Сайт: https://rubbles.ru/ Поделиться
Поделиться



